

libSQL: Diving Into a Database Engineering Epic
Preparing SQLite for the upcoming decades

Few pieces of software enjoy a success as wild as SQLite. It’s now shipped by default on Mac OS, Windows, Android, iOS and many flavors of Linux. It’s used by countless apps in a wide range of industries including aviation, military and space. It’s unsurprisingly the most widely used and deployed database. Not only that, it’s also in the top 5 most widely used and deployed software library across all languages at any point in human history.
This is not possible without strong engineering ethics. Being used in several critical fields where human lives could be at risk means bending to the stringent rules of the industry in question. Aviation for example had relatively insane rules for shipping softwares even before the era of TDD. And SQLite, despite being run by volunteers incorporated those standards early on. The project on top of this provides long-time support and a guarantee of backward compatibility. The massive adoption of SQLite by the biggest players in the tech field is a testimony to the value of the project, but, it’s also an extraordinary burden placed on the developers not to bring in mediocrity.
A fork of SQLite, if it can dare be forked, is pure madness if they intend to be serious about it. They would need to provide the same guarantees as SQLite. Stable, reliable, and dependable software means the introduction of careful, slow-moving changes. Innovation might sometimes be a radical change of components to unleash more powers, which in turn spells out instability, a huge put-off. The team behind the fork must be competent. The SQLite team with decades of experience, codebase intimacy and field specialization already pushes improvements to the limit. To be able to propose alternatives, you must have a good notion of databases to craft an even better product. And wisdom. If a fork of a car is a plane, there are two drawbacks: car users will most probably abandon it as it’s no longer a car. And, since it’s a plane, it will be compared to planes, it must be up to the level and satisfy plane users. The leadership team must be able to find a purpose to the project, fuel motivation for a long time to come and make sure great people remain around even if nobody adopts the project, a hard challenge to answer.
And indeed, many projects do not fork SQLite. They add components over SQLite and package it as an improved project. Forks of SQLite exist. They come and crumble. But, sometimes ago an unusual fork appeared: libSQL. This post discusses libSQL and it’s jaw-dropping team, the technical challenges they overcame, the adoption strategy they put in place, the production validation scheme they concocted, the ongoing development, the coma of future roadmap checkpoints, how features resonate more than fully with a cloud-dominated industry and why it’s the grandest, noblest and most soundly engineered forks of sqlite of all time.

The legend that is SQLite
To understand libSQL, we must first understand SQLite. The inexorable pervasion of SQLite calls for a look at the maintainers, vision, codebase and coding standards. We’ll also have a brief overview of the internals.
The SQLite devs currently aim to support the project through 2050. Whatever happens, they commit to support the project. They also have the source code automatically replicated in several locations around the world. The project has extensive testing both code-wise and end-user-wise. Many Open Source projects have so many users that they don’t worry about unit tests. SQLite introduced aviation-grade tests to ensure high-quality software. Throughout the many interactions with big companies, the deployment at massive scale contributed to solve bugs that the testing suite could not ever catch. Thus, SQLite enjoys top notch excellence. You can read more about the evolution from a hobby project to where it is today. They also pledge not to give in to new fashion trends just for the sake of it, labeling under the “old school“ point.
Every machine-code branch instruction is tested in both directions. Multiple times. On multiple platforms and with multiple compilers. This helps make the code robust for future migrations. The intense testing also means that new developers can make experimental enhancements to SQLite and, assuming legacy tests all pass, be reasonably sure that the enhancement does not break legacy.
The codebase is a pleasure to read. It is well-commented. The project is also well documented. Well-commented means that you can sit down and read the source code like a book. This project is the personification of how good Open Source projects should be. It is a robust piece, but it’s one we can recommend any beginner to start with. Even people who don’t know C can browse and follow along. It’s a long read for sure but very enjoyable.
The SQLite source code is over 35% comment. Not boiler-plate comments, but useful comments that explain the meaning of variables and objects and the intent of methods and procedures. The code is designed to be accessible to new programmers and maintainable over a span of decades.
SQLite devs and particularly the author has a solid background in programming. He worked at bell labs and did his Phd in compiler craft. SQLite was designed with a bytecode engine from the start. The author is not afraid to spin up his own implementations. He is dissatisfied with Git and similar CVS systems. He wrote his own, named Fossil, used by the project. He likes to build his own stuffs. It trickles down to the database engine, B-tree layer, parser (he is allergic to YACC, BISON) and even the editor he writes SQLite in. This shows his incredible mastery over a wide range of topics as well as a bold spirit. Generally people avoid this. But, for SQLite, it turned out to be a predictable advantage in terms of stability as they don’t have to worry about 3rd party codes surprise breaking changes and being license-worry-free.
As expected, SQLite has a consortium to preserve and keep the project ongoing. It has a team of 3 developers. Yes, not a crowd-full driven project. It’s also one of the dark points. SQLite rarely accepts contributions. It is maybe warranted by the fear of sacrificing quality. The source is open but the project is not open to participation. There is no contribution guide to begin with. It’s a model that works, we agree. It challenges the popular concept of Open Source being open to all and everything under the sun, even poor quality contributions, just for the sake of being open.
How libSQL masterfully navigates the challenges of forking
libSQL began with strong footholds. First and foremost, the team has prior experience with the Linux kernel, being on the contributing as well as maintaining side. They also enrolled top ScyllaDB contributors with members having 500 to 1000+s commits. ScyllaDB is the production db which Discord sings it’s praise in the trillion messages handling post.
The people who forked libSQL come primarily from a company called ChiselStrike Turso. But, libSQL is an independent project, accepting outside contributions. To this date, libSQL has seen many outside contributions.

To test out libSQL’s worth, libSQL is used by Turso’s edge service. This brings in feedback about the state of the fork in production. There is at least one serious adopter of libSQL.

Turso brings SQLite to the edge. This is a fine testimony to the feats that libSQL is capable of.
People ranted a lot when libSQL was announced. The project was deemed as a startup fad with no serious work and a fork doomed to fail. Some 09 months later, it’s functional with validated efficiency and pleasant community interaction experience.
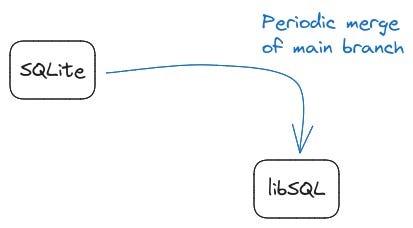
It also periodically merges in the advancements on main SQLite.
How SQLite works
To understand the brillance of libSQL, we need to understand how SQLite works first. The SQL code is passed through the library which in turn deals with the files. It’s as illustrated below.

This big picture of things is enough to conceptually understand SQLite. We’ll zoom in on specific aspects as we focus on libSQL features.
The features of libSQL
When we talk of libSQL, we are talking of 2 main projects:
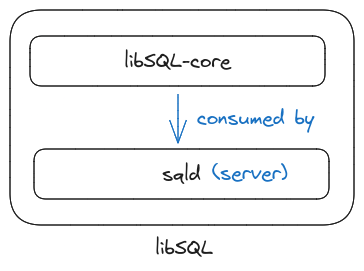
The fork of SQLite
The server version setup on top of the fork, called sqld

Wire protocols
A wire protocol is just a way to talk with the server.

The client takes the query and uses the driver to send it to the server.

Once the connection is establish then exchanges take place between the client and server.
libSQL supports some wire protocols including Postgres and http.
Postgres wire protocol
libSQL allows you to communicate with it’s server via tools implementing the Postgres wire protocol.
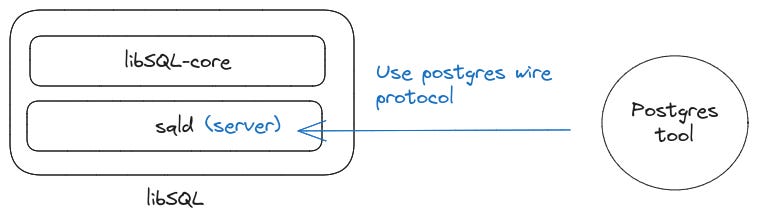
This works perfectly.
Using the feature involves spinning up sqld and using psql (A terminal-based client for postgres) to connect.
$ sqld -d foo.db -p 127.0.0.1:5432 --http-listen-addr=127.0.0.1:8000
$ psql -q postgres://127.0.0.1
appinv=> Psql does not detect it’s not really Postgres at all!
However, many tools relying on the protocol also look for internal postgres table. So, this option is limited in use.

The Hrana protocol
Hrana (from Czech "hrana", which means "edge") is a libSQL protocol to connect to sqld via web sockets.
Tcp connections are banned from many edge runtimes like cloudflare workers, but not web sockets. Hrna is a simple protocol, requiring fewer rountrips than postgres wire.
Servers traditionally connect to a server.

The sqld using Hrana connects through a stream.
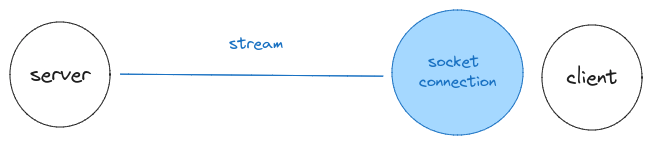
Traditional servers have connection pools.

sqld’s stream supports multiple sql streams. Only once connection is needed to support concurrent requests.

Though intended to be used with sqld, Hrana can also be used with SQLite via a proxy. Hrana protocol defines arbitrary strings with optional parameters, making it easily adaptable to SQL dialects.
Hrana operates on top of the web socket protocol as a sub-protocol. It is stated in the Sec-WebSocket-Protocol.
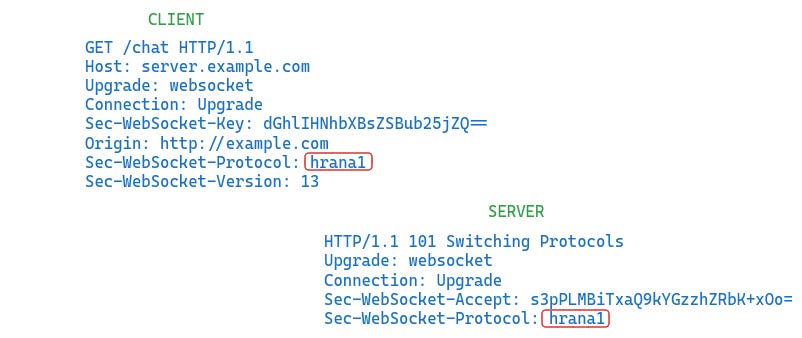
The HTTP protocol
The HTTP protocol allows us to stream Hrana specs where there is little or no web-socket support. Requests and reponses might look like this.

sqld groups requests together using baton values in streams. A baton value is a value sent by the server which should be sent back by the client.

This makes it very convenient to communicate with Hrnana with curl or code simple clients. Here is a json example.
$ curl -s -d "{\"statements\": [\"SELECT * from databases;\"] }" \
http://127.0.0.1:8000
[[{"name":"libsql"}]]Virtual WAL
There are two modes (read this) by which SQLite ensures data is not corrupted and can be recovered in case of a power loss. These are the Rollback and WAL modes. They are mutually exclusive. The WAL mode is more powerful but, for compatibility reasons, the Rollback mode has not been removed. The WAL mode allows reading and single writer writing at the same time.
To understand what a virtual WAL means, it’s good to understand how the Virtual File System (VFS) or OS layer works. Since SQLite is available on many operating systems, writing files to the system is done by a call to the VFS layer. Windows and Unix VFS is included by default.
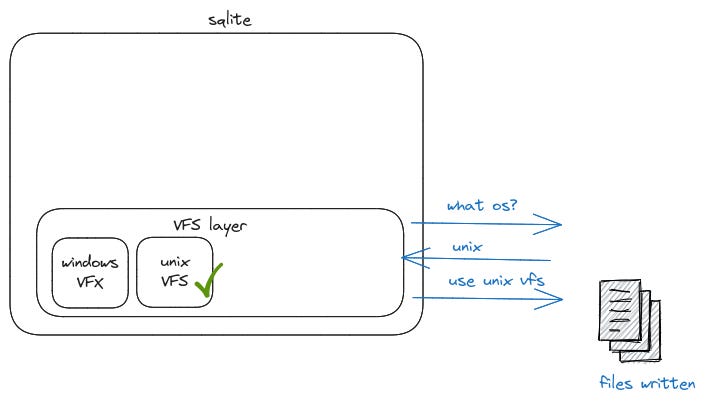
It is also possible to author our own VFS if we want to support another operating system for example.
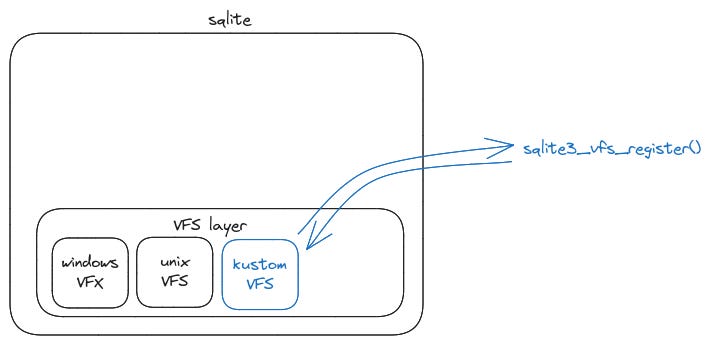
Sometimes we might want to do additional tasks with an established VFS. In this case we wrap the VFS with our VFS along with our code and register our own VFS. Such a VFS is called a shim.

Virtualizing the WAL operations lets us have our own backends, just like we do with VFS. We can specify where to write our WAL files and what to do when these files are being written. Let’s say we want to write them to AWS, we can. libSQL provides some virtual WAL methods
libsql_wal_methods_find
libsql_wal_methods_register
libsql_wal_methods_unregisterBottomless WAL
libSQL (sqld) offers a way to backup WAL files to S3 for backup.
The steps for bottomless WAL is as follows:
1. libSQL writes WAL frames
2. These frames are asynchronously replicated to S3 in the background, in batches
3. When a CHECKPOINT operation occurs in libSQL (checkpoint is an op which compacts WAL frames to drop ones that are out-of-date), we also upload a compressed snapshot of the main database file to S3
4. The snapshot files can be managed through the bottomless-cli
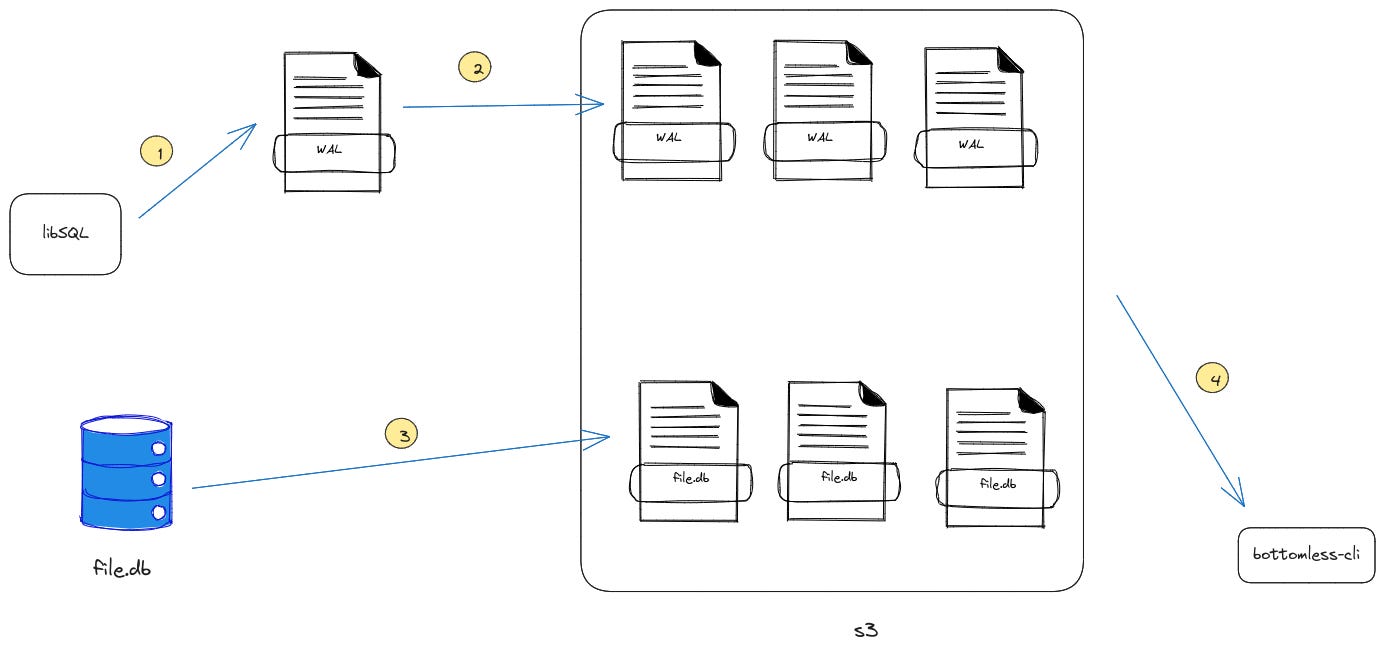
To understand how it works, we must first understand what consists of a WAL file.
A WAL file can have 0 or more frames. A frame consists of a header and a page.
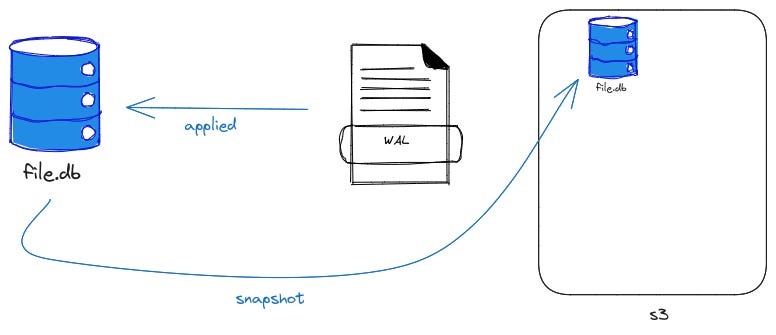
After 1000 frames or 10s or as configured, the frames are gziped and sent to s3.

A checkpoint operation is one where the contents of the WAL file is applied to the database.
After a checkpoint operation, a database snapshot is sent to s3.
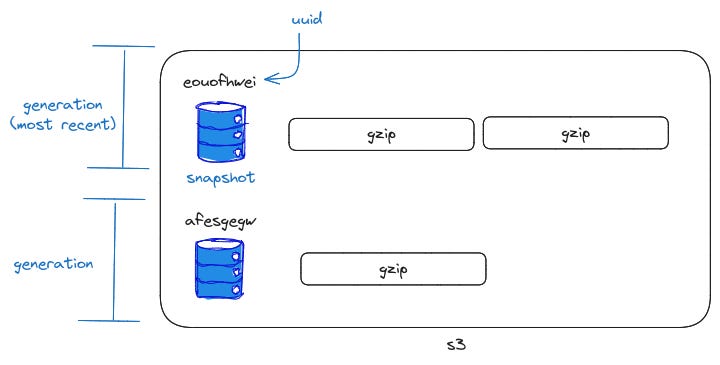
The s3 is organized jnto namespaces called generations. A generation is the period between checkpoint operations. The most recent generation is at the top.
To apply a backup, we specify a snapshot and pull the frames.

To apply the transactions, libSQL makes use of a transaction cache to verify transactions.

Now, when applying the transactions, if it is too big to fit in memory, it is flushed to a temporary file.
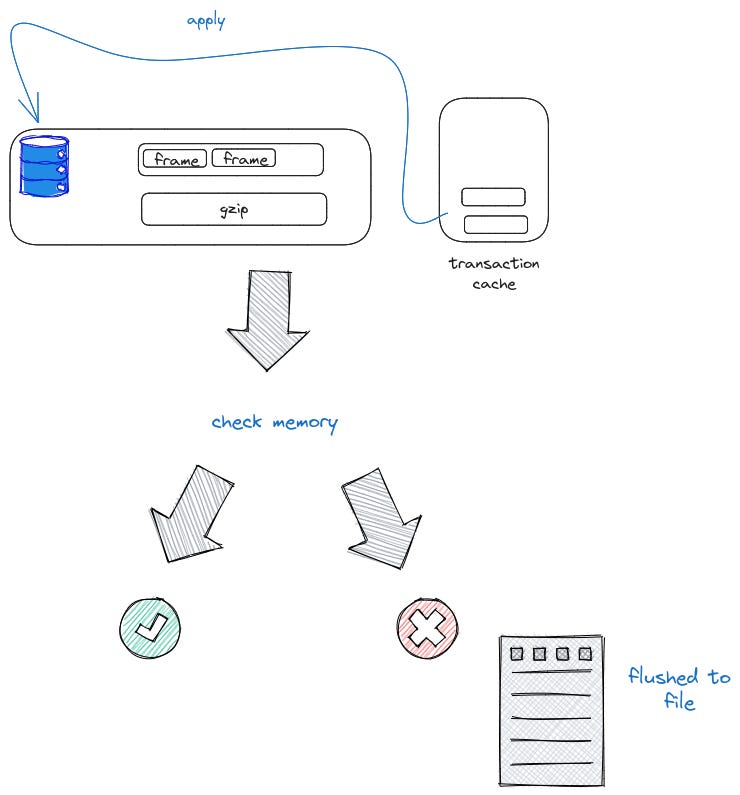
libSQL has 2 counters which when they tally, a checkpoint operation occurs. libSQL has WAL method xframes to increment counter if transaction is committed.
libSQL xcheckpoint to delay checkpoint until a task is completed.
Virtual table callback
A virtual table is an object which does not mirror a table on disk.

libSQL exposes a callback xPreparedSql that allows a virtual table implementation to receive the SQL string submitted by the application for execution.
User-defined WASM functions
SQLite allows you to define your own function using low-level C api.
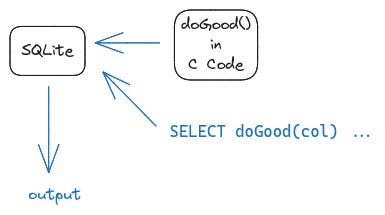
libSQL in addition allows you to define your functions in WASM.
CREATE FUNCTION doGood LANGUAGE wasm AS '<paste WASM bytecodes here>'
SELECT doGood(col) ... -- use hereWe can write and compile our functions using any language we want to WASM. Then we copy paste it in our source code.
You can try it live.
Replication: Bringing data to the edge
libSQL can also be replicated to the edge. Bringing data to the edge currently setting up a primary database and replicas.

Replicas can be server-based or non-server-based called embedded replicas.

Data requested is read from the closest replica.

Once a write occurs, the replica sends data to the primary which replicates the data.

This occurs as follows:
1. The client sends the data to the replica
2. The replica sends the data to the primary
3. The primary replicates the data everywhere
Replication mechanism
libSQL operates on a pull-based mechanism. The replica routinely asks for new frames.

Replicas also keep log files.
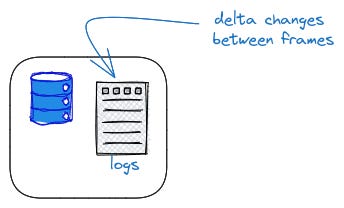
The log files are routinely compacted by simplifying operation records to mean the same thing but in a more compact form.

They opted for this pull-based model instead of say the Raft algorithm to prevent some roundtrips (thereby saving time) and respond to the challenge of the edge.
It is to be noted that the WAL file has been modified to hold frame infos.
The future
They aim to change few things, notably the pull-based model to a node-based model. Multi-tenancy is also being worked on hard. This will allow segregation of data, better replication and gdpr compliance for businesses wanting only some customers data to be stored in Europ.
Parting words
The db included mind-boggling features from scratch. The features were well-thought of and executed. I could not cook up a title fancy enough to demonstrate the amount of work which went into the db.
Massive thanks to the Turso team, specially the devs behind: Glauber Costa, Pekka Enberg, Piotr Sarna, Marin Postma, Bartosz Sypytkowski for dedicating time to explaining things to me.
This was in preparation of my MSCC DevCon (larget IT conf in the Indian Ocean) talk entitled: libSQL: taking SQLite to the moon.
