

Ruff: Internals of a Rust-backed Python linter-formatter - Part 1

Ruff is a Python linter that is extremely fast, deriving its speed from Rust. Companies use linters to ensure that the codebase is as they like. And so, they code rules in linters to ensure they enforce the rules they want.
Typically, linters are run on submitting pull requests or on committing when using pre-commit. If the time taken to run linters on each commit falls in the minutes range, which happens for big codebases, it becomes annoying.
That’s why people love super fast linters personified in Ruff. Today it’s been adopted by projects like Pandas, FastAPI, and Apache Airflow.
The name Ruff comes from ‘a rough prototype’ as the first version was a release shipped to gauge interest and evaluate usefulness. It was built to prove that Python tooling could be much, much faster.
What is Ruff exactly?
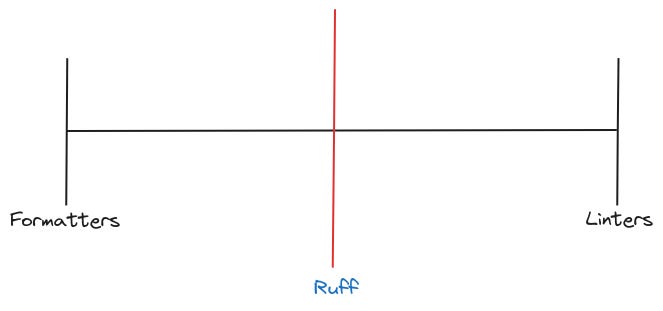
Ruff falls in the middle of the spectrum. It mixes formatting like black does and linting like Flake8. It was originally based on Flake8.
Black takes the Concrete Syntax Tree (CST) and reformats it. It does not know which function has been called. Ruff also highlights logical issues.
Ruff typically views how linters operate and what rules they propose. Then those rules are natively coded in Rust in high fidelity. They also try to use the same test suite of those tools.
Exhaustiveness
It re-implemented the rules of many packages from scratch, including: autoflake, eradicate, flake8-2020, flake8-annotations, flake8-async, flake8-bandit (#1646), flake8-blind-except, flake8-boolean-trap, flake8-bugbear, flake8-builtins, flake8-commas, flake8-comprehensions, flake8-copyright, flake8-datetimez, flake8-debugger, flake8-django, flake8-docstrings, flake8-eradicate, flake8-errmsg, flake8-executable, flake8-future-annotations, flake8-gettext, flake8-implicit-str-concat, flake8-import-conventions, flake8-logging, flake8-logging-format, flake8-no-pep420, flake8-pie, flake8-print, flake8-pyi, flake8-pytest-style, flake8-quotes, flake8-raise, flake8-return, flake8-self, flake8-simplify, flake8-slots, flake8-super, flake8-tidy-imports, flake8-todos, flake8-trio, flake8-type-checking, flake8-use-pathlib, flynt (#2102), isort, mccabe, pandas-vet, pep8-naming, pydocstyle, pygrep-hooks, pylint-airflow, pyupgrade, tryceratops, yesqa. And, that’s a lot.
Another reason to use Ruff then, is that it saves you installing tons of plugins.
How Rust and Python inter-operate
Ruff uses Maturin. PyO3 describes Maturin as a tool that configures PyO3 in an optimum way so that you can focus on development instead of Py03 configuration. This also means that crates.io packages are available directly in Python.
Typically Maturin is used as follows:

But, Ruff uses Maturin to package the pure-Rust binary which is then uploaded to Pypi.

The story behind
Charlie Marsh, the maintainer behind Ruff started coding the project without being a Rust programmer. They had a project at work where they needed to download petabytes of image data for machine learning and computer vision. They tried many Python approaches to speed up the project like multi-processing etc. But, it was not as fast as they wanted. They finally wrote the time-consuming part in Python and exposed it in Rust.
Charlie was seeing how typed languages were helping web development. He was asking whether Python tools had to be written in Python. He decided to code a linter sort of, in Rust, called in Python.
OpenSource success: starting without knowing anything
Since for big codebases, linters were slow, Charlie decided to tackle this problem. He coded a minimal project with 20 rules. The performance did not turn out to be worse. He did not know if people would be interested in the project and released it anyway.
Charlie was not a system programmer or a typed language expert. He wrote a few C lines during his university days and does not recall writing C++ ever.
He had to learn Rust from scratch.
If i can learn it, you can
— Charlie Marsh
The biggest endorsement for Rust Charlie says is the learning experience. The community is great and he managed at the end of the day to do what he wanted. The learning curve is tough though and Rust requires thinking differently. He also appreciated the quality of crates available. It was also pleasant to hear contributors who never coded in Rust making contributions.
He learnt Rust while building Ruff.
He knew nothing about coding linters. He read tons of source code, like going over pyflake, pydocstyle and pycode style codebases. He prioritized shipping features over understanding all that’s happening.
He adopted a daily release schedule and listened to feedback from early adopters. One early big adopter had 100s of modules in a mono-repo and wanted to have configs for each module. They complied. They also solved issues not yet solved with other tools. Each release brought power to users.
Terms explained
compiler theory terms
For the sake of this demo, let’s assume that we have a language like this
x = 5
def sum(a, b):
y = 6
def check_number():
passLexer
A lexer will go over the source code and identity elements

then it outputs lexemes

Parser
The parser takes the lexemes and outputs an AST
AST (Abstract Syntax Tree)
An AST might look like this, different projects have different representations

Different projects take different approaches. Some have a parser that produces a parse tree which is then converted to an AST. Some don’t consider a lexer to be useful at all and directly build a tree with a parser. There are no fixed rules.
The purpose of an AST is to have a representation where it is easy to navigate the source code. From there we can execute the program or flag style issues.
CST
A concrete syntax tree is a tree that retains the source code as it saw it.
How the first-ever version of Ruff worked
The first-ever version of Ruff used the following Rust packages
fern: for logging
rayon: for parallelizing computation
clap: for cli argument parsing
serde: for serializing and deserializing data
rustpython: for parsing, uses the provided AST
colored: for adding colors to the terminal
walkdir: for walking a directory recursively
anyhow: Flexible concrete Error type built on std::error::Error
The source was very minimal and looked like this:
bin/main.rs
cache.rs
check.rs
lib.rs
linter.rs
message.rs
parser.rsThe project was first called rust-python-linter, from the cargo.toml
[package]
name = "rust-python-linter"
version = "0.1.0"
edition = "2021" // First commit from Aug 09, 2022 thoughThe flow looks like this:

It translates to this logic:

The relevant part from main.rs searches for files ending with .py
let files: Vec<DirEntry> = WalkDir::new(cli.filename)
.follow_links(true)
.into_iter()
.filter_entry(is_not_hidden)
.filter_map(|entry| entry.ok())
.filter(|entry| entry.path().to_string_lossy().ends_with(".py"))
.collect();Then it passes the files in parallel to check_path, collecting the result in an array called messages.
let messages: Vec<Message> = files
.par_iter()
.map(|entry| check_path(entry.path()).unwrap()) // this line
.flatten()
.collect();Then in check_path, each path’s AST is loaded and passed to check_ast. The parser comes from RustPython.
pub fn check_path(path: &Path) -> Result<Vec<Message>> {
// ...
let python_ast = parser::parse(path)?;
let messages = check_ast(path, &python_ast);
cache::set(path, &messages);
Ok(messages)
}The meat of the linter is this part.
pub fn check_ast(path: &Path, python_ast: &Suite) -> Vec<Message> {
let mut messages: Vec<Message> = vec![];
for statement in python_ast {
let Located {
location,
custom: _,
node,
} = statement;
match node {
StmtKind::FunctionDef { .. } => {}
StmtKind::AsyncFunctionDef { .. } => {}
StmtKind::ClassDef { .. } => {}
StmtKind::Return { .. } => {}
StmtKind::Delete { .. } => {}
StmtKind::Assign { .. } => {}
StmtKind::AugAssign { .. } => {}
StmtKind::AnnAssign { .. } => {}
StmtKind::For { .. } => {}
StmtKind::AsyncFor { .. } => {}
StmtKind::While { .. } => {}
StmtKind::If { .. } => {}
StmtKind::With { .. } => {}
StmtKind::AsyncWith { .. } => {}
StmtKind::Raise { .. } => {}
StmtKind::Try { .. } => {}
StmtKind::Assert { .. } => {}
StmtKind::Import { .. } => {}
StmtKind::ImportFrom {
level: _,
module: _,
names,
} => {
for alias in names {
if alias.name == "*" {
messages.push(Message::ImportStarUsage {
filename: path.to_path_buf(),
location: *location,
});
}
}
}
StmtKind::Global { .. } => {}
StmtKind::Nonlocal { .. } => {}
StmtKind::Expr { .. } => {}
StmtKind::Pass => {}
StmtKind::Break => {}
StmtKind::Continue => {}
}
}
messages
}Then it matches the node, pushing a message when there are star imports.
Then the collected messages are displayed in main.rs.
if !messages.is_empty() {
println!("Found {} error(s)!", messages.len());
for message in messages {
println!("{}", message);
}
}Simple but powerful if you ask me. Besides that, caching was included from day 1. It was inspired from ES lint caching [1]
Ruff now
The Ruff codebase has a lot of contributing opportunities. There is Ruff, Python, bash, TypeScript, and markdown to choose from.

There are also other folders and files as well but these are the main ones. We will interest ourselves with the crates folder.
Here are some notes about crates/. It is to be noted that not al crate components are used / called within the project, like ruff_wasm for example.
Evolution of the parser
Rust used the parser from RustPython. Then it maintained a version of it in the Ruff repo.
Then it switched to a parser generator, where the language is defined using a DSL and then the generator generates executable code for the parser.
Right now it uses hand-written recursive descent parser.
Language-server protocol
Ruff also provides a language server as part of the codebase. If you want Ruff to integrate with an existing IDE for Python, you can!
More on Ruff now in Part 2
Resources consulted
The Ruff Discord, a living encyclopedia
Hey Abdur,
thanks for the post!
This is a great post!