

Scuba: Diving into the extraordinary system Facebook uses to analyse millions of events per second
Take your snorkel, we gonna go deep.

Scuba, a distributed in-memory database, is the system at Facebook that aggregates events for monitoring. This post sources its material from the two Scuba papers, namely: “Scuba: Diving into Data at Facebook” and “Fast Database Restarts at Facebook”, giving preference to the second. It’s written as if the two papers were one, with powerful visualizations. It’s concise as it strips away discussions about alternative decisions. Ideally, reading the papers is encouraged after going through this post as they give additional details here and there. It also discusses recent improvements at the end. Scuba has had 4 generations [3]. The bulk of this article focuses on the 1st generation and the 2nd generation partially. The 3rd and 4th generations are touched when public data is available.

When a Facebook engineer (Thanks James Luo) shared Scuba with me I was blown away. The massive scale at which it operates and its mind-boggling performance, usefulness, and love index at Facebook motivated me to explore its internals, as well as the Facebook ecosystem like Scribed, Calligraphus, Hive, LogDevice, FbThrift, and Scribe. Let’s start.
Table of content
Intro
Overview of Scuba
Query processing
Storage
2019 updates
Design notes
Parting words
Intro
Scuba is fast and scalable, ingesting and exiting millions of events per second! And what’s more, it’s designed to use cheap, common machines!

The events are stored on hundreds of servers having 144GB of RAM.

Developers can then query these events which run under a second on live data.

The system caters for a wide range of events like a code change checked in and request from phone. It can co-relate one metric over another e.g. ads revenue and user engagements. If for example both dropped we know it’s an external factor causing it.

It’s named scuba as it enables you to dive deeper into your data.

Scuba started as a discussion to partition a MySQL database. The original back-end was coded as part of a hackathon by David Reiss (Still at Fb, a whopping 16 years). Lior Abraham (Now founder of Suba.io) coded the front-end during a couple weeks of frustration with current tools. The backend functionality was greatly expanded on and scaled up by John Allen. Okay Zed (currently back at Fb) made the front-end far sleeker and more functional.A then summer intern, Oleksandr Barykin, improved the worst query times by an order of magnitude. Then it was improved on countless of times [1].
Overview of Scuba
Scuba uses the Thrift API extensively. Thrift is a serialization and RPC framework for service communication, originally closely following Apache Thrift. Scribe is the log ingestion framework used at facebook, with LogDevice for log storage. LogDevice is a scalable and fault tolerant distributed log system. Ptail was coded to view LogDevice logs, originally a hack which remained permanent and used as the data source point for systems at Fb, including Scuba. It is to be noted that Scribe is not only for file-based logs, but also accepts messages and pub/sub blurring the line, in line with the definition of a log being “an append-only, totally-ordered sequence of records ordered by time”.
The tailer component fetches data from Scribe and sends it to a leaf server, where a backup is stored to disk and a compressed version is sent to memory. Scuba’s compression methods are a combination of dictionary encoding, bit packing, delta encoding, and lz4 compression, with at least two methods applied to each column (Data is stored in memory as tables with rows. A columnar approach is chosen as a newer upgrade as the main purpose of Scuba is analytics). Data is deleted when it’s age or space limit is reached. The streaming platform deals with load-balancing and outages for the tailer component.

From what we gather, Scuba machines consist of an aggregator server (to aggregate) and leaf servers, one per core, currently 8 per machines.

To send the rows, tailer selects 2 leaf servers and chooses the one with more memory. If they are not alive it continues to choose until it has what it is looking for.

Scuba communicates with clients using Thrift API. Scuba provides:
Forms, which users fill and see charts
An SQL cli to execute queries
Alerts service

Besides those 3, people can code their own scripts using the Thrift API in their language of choice.
It is to be noted that in the case of high volume data, only a sample is stored.
Query processing
First a root aggregator machine is selected

Then it selects 4 machines to act as intermediate aggregators.

The intermediate ones locate 4 more machines

Then the query is passed to leaf servers

When a query comes, it is distributed across all leaf servers for maximum parallelism and gathered back with stats like whether each Leaf contained the table, how many rows it processed, and how many rows satisfied the conditions. It is sent to the intermediate aggregator that called it.
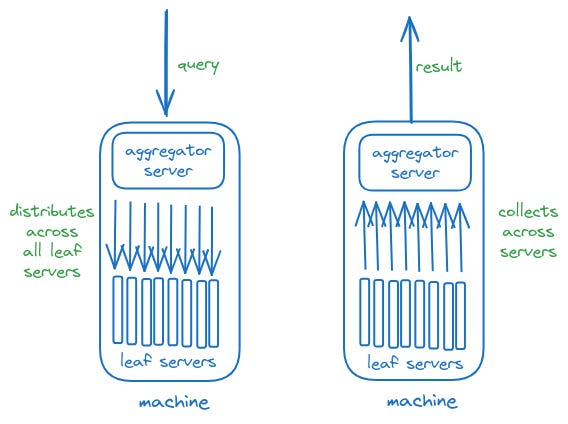
The intermediate aggregator consolidates the result and sends to the root aggregator for further processing which returns the result back to the waiting client. If aggregators or leaf servers don’t respond within a certain amount of time, they are omitted from the result. If not all servers are available, the results return with the amount of data they processed.
Storage
When there are planned upgrades, servers are gracefully shut down and their data copied. When they turn on again, the memory is restored.

Here is the data layout for the two memories. Note the differences between them. Having two separate structures allows for heap memory format modification, useful in the case of experiments.
Rows are sent but stored as columns, with row blocks storing compressed data. Restarts can also load data from disk instead of shared memory if the corresponding bit for shared memory is not set.
Developers are free to modify their rows as they wish, adding in fields required for monitoring as the spirit is to encourage people to monitor, and worry about volume later.
Restarting data from memory requires 2 - 3 minutes compared to 2 - 3 hours for disk. It’s a fast rollover solution for Scuba. This technique was already being used by the Memcache and TAO teams at Facebook. Restart is done using only 2% of Scuba servers at a time, leaving 98% available for queries. Only 1 leaf server per machine is restarted. This allows a restart of the entire cluster in under one hour.
2019 updates
As of 2019, Scuba was handling high Petabytes and 100k tables, as opposed to low Tbs and 100s tables when it first started. To handle the load, the infrastructure was improved.

The Tailer component now operates in 3 regions, same for the backend, the backend is now using Flash storages.
Additionally, requests to the backend pass through the backend’s edge proxy then origin proxy then goes to the root aggregator.
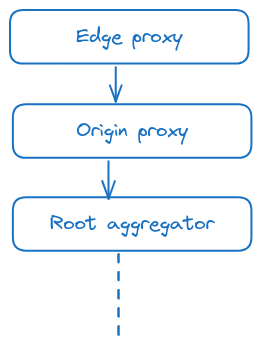
The best results is sent back to the user.

Presto, a distributed SQL query engine developed at Fb was also added in a bi-directional way to allow querying of historical data and live data. With the integration of warehouse data, users can now query data in a time frame, with the results stitching live and historical data.
Design notes
Scuba aims to achieve 2 - 3 s P95 latencies and 10-100ms average query latency and data available 1 minute after being published.
Scuba needs to:
Ingest data fast: In-memory stores are used, typical in append-only systems
Be interactive: Needs low latencies, queries are designed to be processed in parallel
Support Ad-hoc queries: An SQL layer was added with limited features
To make queries fast, caching is used in memory. Joins between tables and global sorting are also disallowed in the fanout tree architecture. Data availability is best effort by design, is not 100% available but compensates by the available volume of it.
Parting words
A holistic, in-depth system like Scuba allows to query events even at the hardware level. Show me a heat map of servers by their CPU consumption. Show me a heat map of racks by their packet throughput.
The system captures well the essence of software: Be powerful, and brilliantly perfomant but spare users the details. Scuba allows developers from all backgrounds to use it. It caters to all users by pre-including common use-cases as forms-to-visualizations, more advanced users can query using the query language. Even more advanced users can interact with it directly using the Thrift API. It even has automatic outlier detection algorithms, without the need to know thresholds. It suggests outlier areas. Being simple to use increased its adoption inside of Facebook.
And yes Fb folks, when will a new Scuba paper be out?
Resources consulted
[5] The history of logging @ Facebook (abridged)
[6] The Log: What every software engineer should know about real-time data's unifying abstraction
Scuba diver image from Freepik
